AI 检测工具本质像查重,误判人类文章成常态
本文介绍了对 AI 文章检测工具的深入分析与批判。文章指出,此类工具的核心原理是让 AI 判断文本是否具有“AI 味”,但这种做法存在根本性矛盾:让一个概率模型去识别何为“莫名其妙”,如同请狐狸看鸡窝。作者对比了绘画 AI 检测的早期有效性,指出其基于 AI 模仿人类新手错误,随着技术进步逐渐失效,而文字检测则更难固定规则。文章进一步揭示,人类写作本身存在大量套路化表达,如公文、营销号文案,这些正是 AI 训练数据的来源,导致自然人类文章常被误判,而故意写烂、杂乱的文字反而能通过检测。作者以论文查重类比,认为 AI 检测本质上是统计模板匹配,不关心是否为人所写,甚至奖励写作水平低下。最终,文章讽刺了当前 AI 检测工具在实际应用中的荒诞现象——原创论文被判 AI,而 AI 生成后手动破坏逻辑的反而通过,迫使人们为通过检测而故意破坏文章质量。
DeepSeek TUI 开源命令行工具,使用体验与修复分享
本文介绍了作者作为 DeepSeek 忠实用户的长期使用体验与最新发现。作者最初被 DeepSeek 吸引,因其开源特性带来代码透明与掌控权,API 按量付费模式对个人开发者极为经济,相比 Claude Code 等按月订阅方案更为灵活。近期因 Trae 引入高价排队机制而放弃使用,转而重新关注 iFlow CLI 但渴望更优的开源替代品。在社交媒体上发现由非专业出身的开发者 Hunter Bown 创建的 DeepSeek TUI,这是一款开源社区出品的命令行 Agent 工具。安装通过 npm 一行命令完成,初始化界面支持语言选择与 API Key 输入,默认使用 DeepSeek V4 Pro 并自动根据任务切换至 V4 Flash 以节省成本。其左侧面板实时展示 AI 当前操作、错误信息及 Token 预估费用,透明化设计让用户清楚每一步进展。作者利用该工具解决了之前由同一模型在 iFlow CLI 中编写的有问题的 PJAX 友链代码,实现了“自己修复自己 BUG”的效果。最后作者计划用 DeepSeek TUI 基于 SMTP 和 RSS 为静态网站搭建文章更新邮件提醒功能,旨在提供更纯粹、不依赖第三方平台的订阅体验,并充分利用闲置的邮箱地址。全文展现了开源工具链的自由度与社区创新的价值。

网站说说迁移:AI 自动标签与长上下文反思
本文介绍了作者将网站说说功能从本地文件管理迁移到远程拉取架构,解决 Git 提交历史臃肿的技术债务。随后,作者重构了标签系统,编写了两个 Python 脚本:auto-essay-tags.py 批量调用大语言模型 API 为已有说说自动生成社交媒体风格标签,essay.py 则用于新增说说时自动获取时间、生成唯一 key 并调用 API 打标签,两者共用同一标签库 essay-tags.md。文章还探讨了在轻量级标签生成场景下,长上下文并非最优解——传递最小必要信息更高效,并质疑当前 AI 厂商依赖长上下文消耗 Token 的商业模式可能扭曲了技术发展方向。
用 AI 自动为博客文章打标签,我写了个 Python 脚本
本文介绍了作者为解决博客文章标签利用率低的问题而编写的 Python 自动化脚本。该脚本利用 DeepSeek API 为每篇文章生成 5 个适合 SEO 的标签,并优先复用已有的标签库以避免重复。脚本自动读取 Markdown 文件,调用 API 后解析返回的标签,插入到文件的 frontmatter 中,同时更新一个标签总和文件,确保每次运行只载入当前文章和标签列表,从而降低上下文熵增。作者还建议配合 Git 管理文章目录以防数据丢失。该脚本有效简化了标签分配流程,提升了博客 SEO 优化效率。
个人网站被 AI 爬虫偷数据,为何我还在坚持更新
本文探讨了作者重新审视个人网站价值的经历。作者通过分析 Cloudflare 后台数据发现,大量访客实为 AI 公司部署在西方的爬虫,它们批量下载中文内容用于模型训练却不贡献搜索引擎索引,导致其个人网站几乎无法被搜索到。作者与朋友的争论引出核心观点:个人网站不是保存工具,而是一个游乐场——配置 CDN、分析流量、甚至与爬虫斗智斗勇的过程本身就是乐趣。尽管知道内容可能被 AI 消化、姓名被抹去,作者仍选择继续更新,因为游戏的意义在于过程而非结局。文章反思了在 AI 时代个人创作的被利用与独特性的消解。
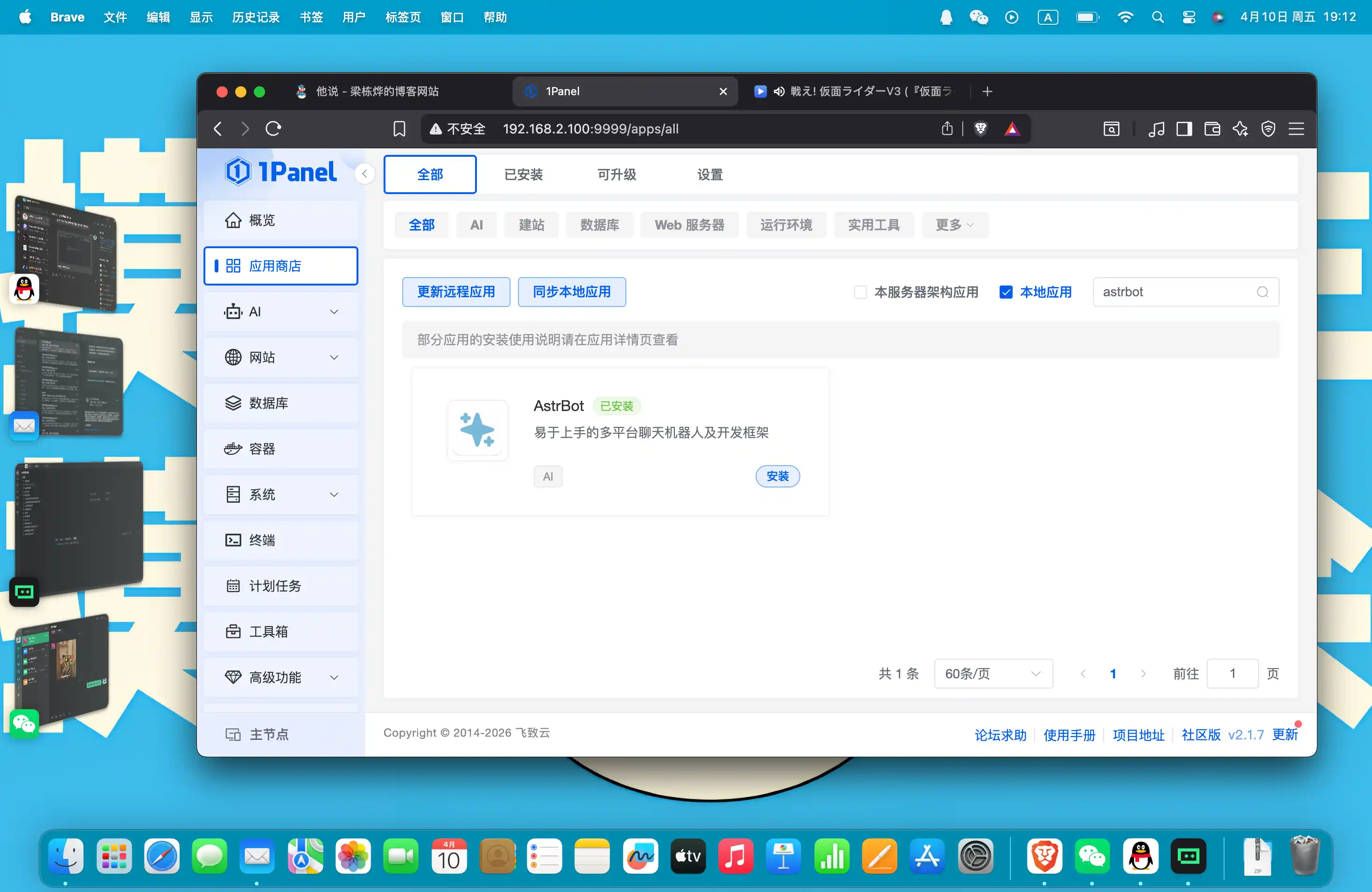
树莓派安装 AstrBot 与 OpenClaw 对比,体验及折腾实战全记录
本文介绍了 AstrBot 机器人软件的安装与使用体验,作者将其安装在树莓派上,通过 1Panel 商店便捷部署。文章详细描述了接入大语言模型的过程,包括生成 API Key 、手动开启模型等步骤,并对比了与 OpenClaw 的差异。对话体验流畅、响应快速,但作者尝试让机器人执行 Shell 命令时失败,后通过插件系统查找权限设置仍未成功,最终呼吁社区帮助。整体评价:作为聊天工具初衷良好,延迟低,但作为 OpenClaw 竞品仍有改进空间。
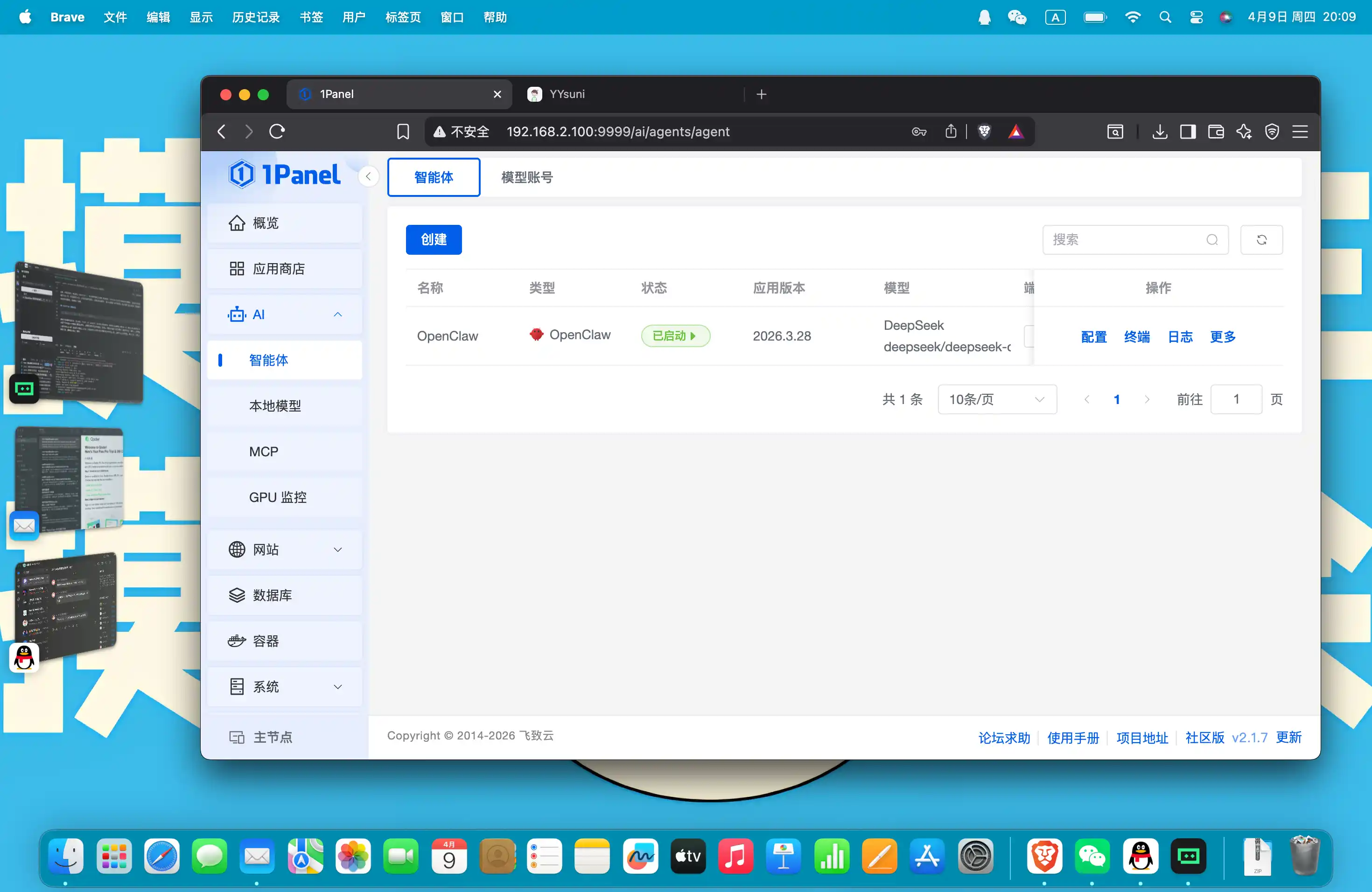
OpenClaw 深度体验:安装难 Token 消耗大,普通人谨慎使用
本文介绍了作者对 OpenClaw 的使用体验与评价。作者指出 OpenClaw 虽然直接安装困难,但通过 1Panel 等图形化工具可轻松部署;其确实消耗 Token 较多,一天花费约 3 元,但并非网上所说的“扣光银行卡”般离谱。耗 Token 的罪魁祸首是默认开启了 46 个 Skill,每个 Skill 的 Description 过长,作者建议关闭不必要的 Skill 以节省成本。对于“使用简单”的说法,作者并不认同,认为其操作仍显黑箱,更适合当作有记忆的智能助手而非项目开发工具。最后,作者认为 OpenClaw 更适合有耐心、愿意投入成本且需要长期陪伴的用户,普通人可能并不适合。
用 Shell 脚本打造 OpenAI API 智能命令行对话机器人
本文介绍了 一个基于 Shell 脚本的终端聊天工具,通过调用 OpenAI API 实现与语言模型的交互。脚本首先提示用户输入 OpenAI API URL、API Key 及模型名称,并初始化一个 JSON 格式的历史记录文件。随后进入无限循环,每次读取用户输入,将用户消息追加到历史记录中,再通过 curl 发起 API 请求,从返回的 JSON 中提取模型回复并显示在终端上,同时将助手回复也更新到历史记录文件,从而实现多轮对话的上下文维护。该脚本简化了与 AI 模型的命令行交互过程,适合快速测试或二次开发。

梦中放烟花道歉,与 Linux 开发者怒斥中文 AI
本文介绍了作者做的一个混乱的梦。梦伊始,作者在大院乱放烟花被提醒违规,慌乱中烟花对准了对面水果铺,最终被迫去道歉。随后梦境切换为新闻场景:Linux 邮件列表的开发者们怒斥中文 AI 破坏了开发环境,作者查看原文发现批评内容不过百字。最后,作者隐约看到母亲质疑厕所烟灰,要求哈气验烟,惊醒后发现自己对着笔记本电脑,而母亲早已在外玩手机,厕所的烟灰实为每日烧艾条所致。文章以荒诞的梦境串联起现实与网络事件,折射出潜意识的焦虑与日常细节的交织。